1. Cluster workflow
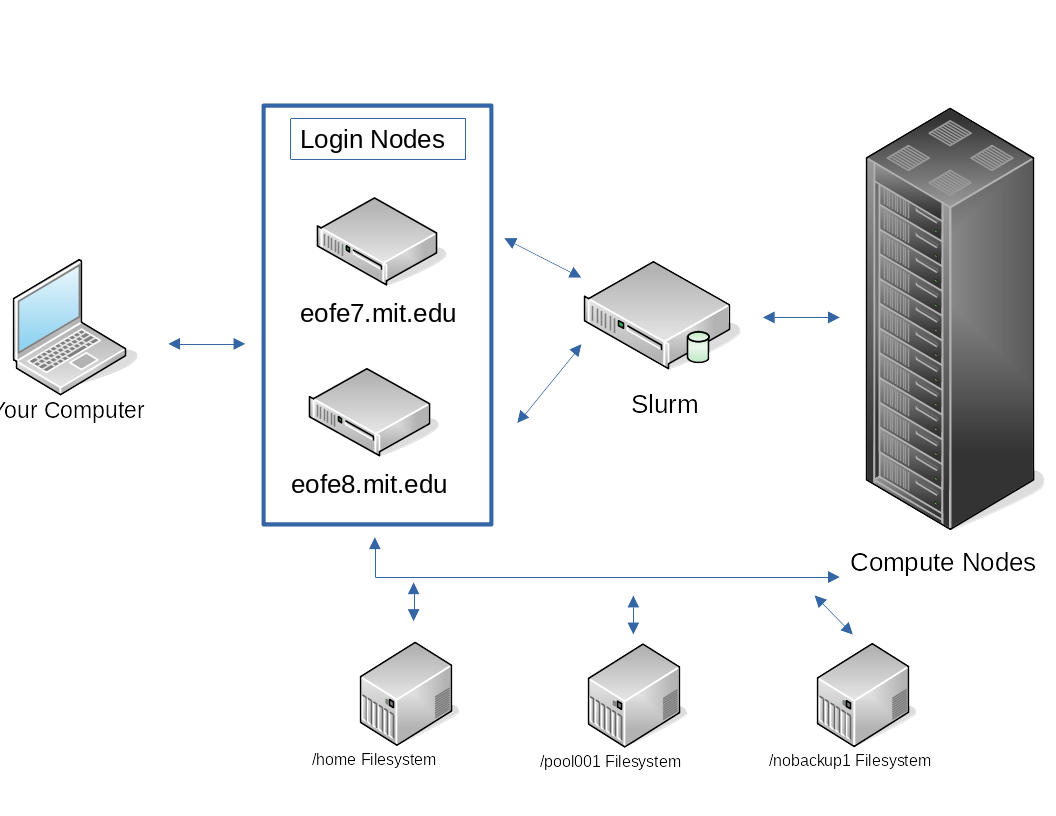
Once you’ve followed the steps here, you will be logged into what is referred to as a “login node” or “head node”. These are the nodes that connect the cluster to the outside world. They are intended for basic tasks such as:
- Managing files.
- Submitting jobs to the compute nodes.
- Uploading and downloading data.
- Compiling software.
While small scale interactive code and tests are allowed to be run on the login nodes, please remember that the login nodes are shared by all users so any resource intensive code must be handled by the compute nodes. Any resource intensive jobs found running on login nodes are subject to being killed without warning.
To run a job on the compute nodes you will need to use the slurm job scheduler to submit your jobs to the compute nodes. This can be done with either srun for interactive runs or sbatch for batch jobs.
To compile software on the cluster for personal use, please see here.